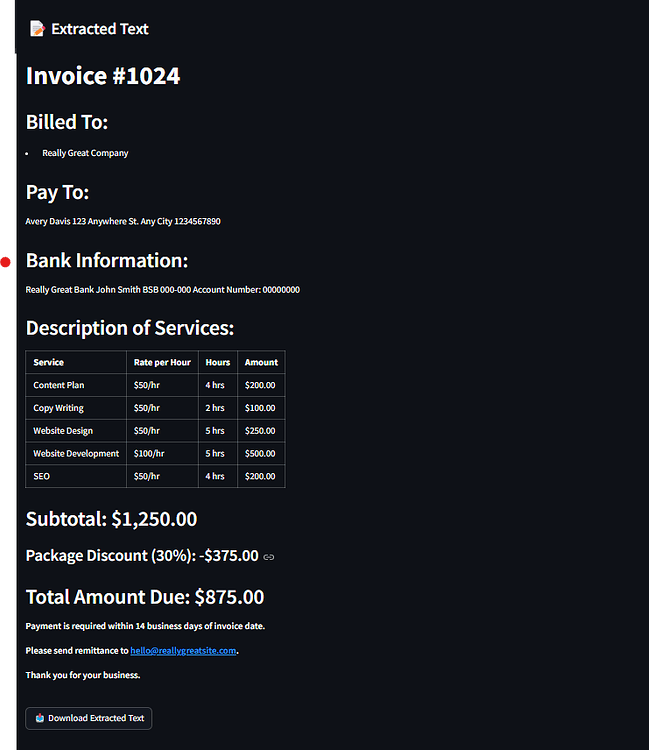
这是一个基于 Ollama 视觉模型的图片文字识别工具,能帮你从图片中提取文字。
- 支持两种视觉模型:
LLaVA 7B:速度快,适合实时处理,就是准确度可能差点
Llama 3.2 Vision:准确度高,适合处理复杂的文档 - 提取出来的文字格式挺灵活:
可以是 Markdown 格式,保留原文的标题、列表这些样式
可以是纯文本,干干净净的
可以是 JSON 格式,结构化的数据
还能识别表格,或者提取关键信息对
GitHub:GitHub – imanoop7/Ollama-OCR
图片:

识别结果: